URL Extractor Tool
Find and extract all URLs from your text with one click
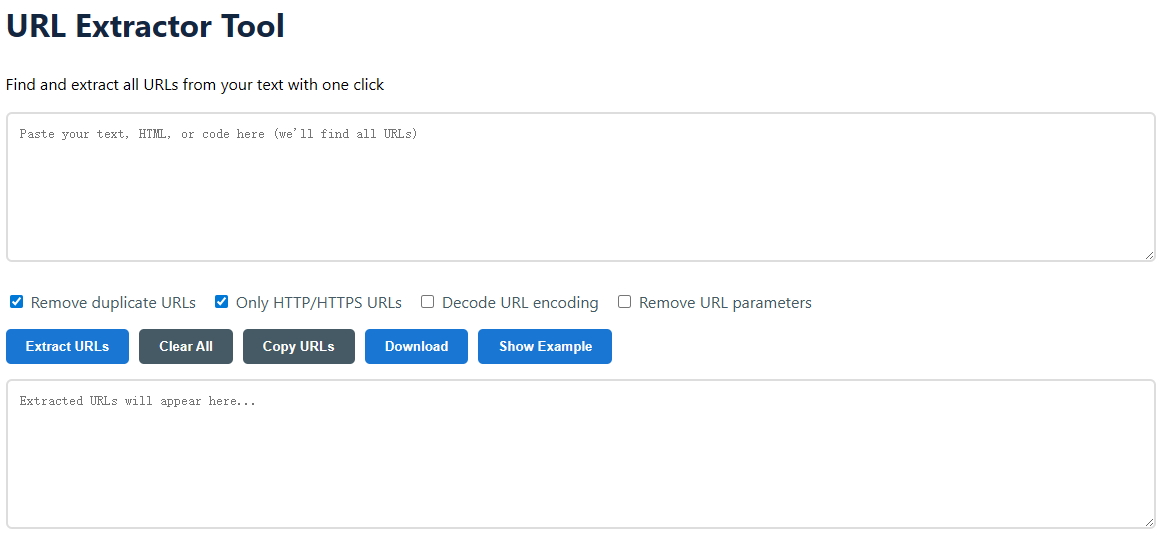
How to Use the Free URL Extractor Tool
Our URL Extractor is a robust, web-based software that can quickly extract and pull out all web addresses from any text block. If you’re a developer going through HTML, a marketing evaluating backlinks or a researcher assembling sources, this application takes a difficult manual task and turns it into one click. It is 100% free, no sign-up, processes your data safely in your browser without sending it to any server. Follow the simple steps below to turn jumbled text into a tidy, actionable list of URLs.
- Paste Your Source Text
- Choose Your Extraction Options
Remove duplicate URLs: Remove duplicate links for a clean list.HTTP/HTTPS URLs only: Regular web URLs only, no mailto: or ftp:.Decode URL encoding: Converts characters like %20 into spaces.Remove URL parameters: Strips query strings (?id=123) to get the base URL.
- Click “Extract URLs”
- Copy, Download, or Analyze
Typical Use Cases for URL Extraction
Manual link collection is inefficient and error-prone. This tool streamlines the process for a great variety of business and personal applications. URL extraction is an essential step in structuring and analysing data, whether it’s for SEO audits or academic study. These are the most common situations where our URL Extractor can be of tremendous value.
- SEO & Digital Marketing: Extract URLs from exports of competitors’ sites or reports from third-party tools to audit backlink profiles.
- Web Development & Debugging: Instantly locate all external resources (scripts, stylesheets, pictures) in HTML, CSS or JavaScript code.
- Content Management and Migration: Batch find all internal and external links in articles before migration to the new platform.
- Academic Research & Citation: Build a bibliography of source URLs from your research notes and draft articles.
- Data Scraping & Analysis: Extract and prepare raw scraped data by removing surrounding text and HTML tags from core URLs.
- Social Media & Community Management: Pull shared links from community forums, comment sections or social media export files.
- Security Analysis: Check logs or reports to find any possibly malicious domains or phishing URLs included in the text.
- Personal Organization: Collect all website links from a long document, email thread or note into a single easy-to-manage list.
What URL Formats Can Be Extracted?
The program uses a complex regular expression (regex) pattern to find a large variety of Uniform Resource Locators. It is designed to identify not only valid, fully-qualified web addresses, but also frequent variants and encodings seen in the wild. Understanding what it can measure can help you interpret your data.
Regular Web URLs
https://www.example.com/pagehttp://blog.example.co.uk/article?id=5https://example.com:8080/path/
Common Variations
www.example.com(Protocol-relative)//cdn.example.net/asset.js(Scheme-relative)subdomain.example.org/path/file.pdf
Encoded & Complex
https://exa%6Dple.com/(Obfuscated)-> https://example.com/http://example.com/file%20name.txt(URL encoded spaces)example.com/page#section(With fragment identifier)
Technical Features & Advanced Capabilities
In addition to the basic extraction, the program provides a variety of smart processing options that help to improve your results. These capabilities will do typical data cleaning chores automatically, saving you time in post-processing. Each of these options is intended to handle a specific challenge when working with URLs derived from unstructured data.
Duplicate Removal
Detects and removes duplicate URLs to give you a clean, unique list. This is important for analytics, link development, and sitemap generation, because counting the same link numerous times would bias the statistics.
Filter by Protocol
If you set “Only HTTP/HTTPS URLs”, the tool will ignore non-web links like mailto:[email protected], ftp://server.com, and tel:+1234567890 and provide you with a neat list of web pages.
URL Decoding
Converts percent-encoded characters to their regular form. For example, %20 is converted to a space and %2F is converted to a forward slash, so URLs are human-readable and consistent.
Parameter Stripping
Strips query strings (anything after the ?) and fragment identifiers (after the #). This aids in canonicalization, page variant grouping and core page structure analysis.
Example: Input and Extracted Output
You get to see the gadget in action, and it is obvious how powerful it is. This is a sample of mixed material with plain text, HTML and a faulty URL. The right column shows the clean, processed output after applying all available settings (duplicates deleted, just HTTP/HTTPS, decoded, arguments stripped)
| Input Text (HTML & Mixed Content) | Extracted & Cleaned URL List |
|---|---|
We have our blog at https://blog.example.com and our main site at http://www.example.com a link: Shop Now Don't forget http://EXAMPLE.COM/About-Us . Email us at [email protected]. Broken mention: htt://bad-url.com. Encoded link: https://ex%61mple.com/file%20name.doc | http://www.example.com/ https://blog.example.com/ https://example.com/shop http://example.com/About-Us https://example.com/file name.doc |
What is the use of our Online URL Extractor?
While many online tools do simple things, ours was designed with precision, user experience and data integrity in mind. We value your time and privacy and aim for a smooth workflow. Here are the primary advantages that make our tool better than manual solutions or other utilities.
- 100% Client-Side Processing: Your data does not leave your computer. Every extraction is done quickly in your browser, assuring your privacy and security.
- No Limits or Registration: Use free of charge and as often as you like. No character limits. No daily quotas. No signups.
- Batch Processing Power: Quickly process big documents, code files or data exports, pulling thousands of URLs in milliseconds.
- Smart Cleaning Modes: The built-in filters (deduplication, decoding, etc.) do extensive data cleaning that would take minutes to do manually.
- Direct Export Options: Copy to clipboard with a single click or download as a .txt file and upload to your existing process.
FAQ (Frequently Asked Questions)
Questions on how the tool works or what it can do? Here are answers to the most common questions we receive. If your question is not answered here, the interface and choices of the program are self-explanatory and intuitive when you use the tool.
Is my data safe when using this tool?
Yes, it is. The entire extraction procedure runs locally in your web browser, using JavaScript. No text that you paste is uploaded to any server, recorded or stored. To prove this, you can load the page and disconnect your internet, and the tool will still work flawlessly.
Can it extract URLs from PDF or Word files?
Yes, but with one step, you will need to extract the text from the PDF or Word file first. Most of the time, you can accomplish this by selecting all text (Ctrl+A / Cmd+A) and copying (Ctrl+C / Cmd+C) from within the document viewer or editor. Copy the text above and paste it into our tool to get the URLs.
What is the function of Decode URL encoding?
In a URL, special characters such as spaces, ampersands, or non-ASCII letters are often replaced by a percent sign (%) followed by hexadecimal codes. This option transforms the codes back to the original legible characters. For example, %20 becomes a space. %C3%A9 becomes "é".
Why aren't some URLs extracted?
The tool is made for accuracy, not guessing. It may miss URLs that are significantly broken (e.g., missing dots like "http://example"), obfuscated with purposeful typos, or written in plain text without a protocol (like "example.com") if they are part of a sentence without clear limits. All filters enabled: highest-quality results for regular web links.